

There are a lot of variations in methods and terminology based on which technology does what, and it has evolved a lot. We talk about online help, context-sensitive help, contextualised help, targeted help, onboarding help, and many others. Some of the definitions are clear, some are linked to specific technologies. What we are seeing is a lot of overlap in the definitions as they have evolved through the years. For us, contextual information for software is all about information delivered at the right time, in the right place and with content adapted to a context in which it is read.
The aim of this article is to establish definitions and methods of production and delivery for use as we move to the needs of Industry 4.0 with IoT and AI for instance.
Google references Online help:
Online help is topic-oriented, procedural or reference information delivered through computer software. It is a form of user assistance. Most online help is designed to give assistance in the use of a software application or operating system, but can also be used to present information on a broad range of subjects. When online help is linked to the state of the application (what the user is doing), it is called Context-sensitive help.
From Google – Online help
There are a lot of proprietary solutions out there to cater for online help – the article referenced just above is full of them.
And Google also references Context-sensitive help:
Context-sensitive help is a kind of online help that is obtained from a specific point in the state of the software, providing help for the situation that is associated with that state.
Context-sensitive help, as opposed to general online help or online manuals, doesn’t need to be accessible for reading as a whole. Each topic is supposed to describe extensively one state, situation, or feature of the software.Context-sensitive help can be implemented using tooltips, which either provide a terse description of a GUI widget or display a complete topic from the help file. Other commonly used ways to access context-sensitive help start by clicking a button. One way uses a per widget button that displays the help immediately. Another way changes the pointer shape to a question mark, and then, after the user clicks a widget, the help appears.
Context-sensitive help is most used in, but is not limited to, GUI environments. Examples include Apple’s System 7 Balloon help, Microsoft’sWinHelp, OS/2’s INF Help, Panviva’s SupportPoint, or Sun’s JavaHelp.
A similar topic is embedded help, which can be thought of as a « deeper » context-sensitive help. It generally goes beyond basic explanations or manual clicks by either detecting a user’s need for help or offering a guided explanation in situ. Embedded help is not to be confused with a software wizard.
From Google – Context-sensitive help
Are you still with me?
So which do we do, online, context-sensitive or embedded help? Do we also do the tooltips? We could probably organise a conference, and debate it.
Sorry to disappoint, but we won’t. We have our own definition for contextual information for software.
The definition we use is contextual information for software
Contextual information for software is delivered directly to a UI element when and where it is needed. Depending on the software technology this form of information is embedded or connected (in which case it appears in a popup element).
In this case, it is very different from the online definition which generally means only pages accessible in web format.
Contextual information is an access point to other forms of procedural, reference, conceptual, training and support information through pertinent linking.
The writing approach used here is based on DITA where micro topics are written when needed. As an author, it implies asking the right questions:
- What is this and/or what does it do?
- How do I use it?
- Do I have an example?
- Where am I in terms of a workflow?
- What next?
- What pitfalls to avoid?
This is an editorial matrix, a content guideline of sorts. By no means are all items to be written exhaustively as if they were a form to be filled.
The form is minimalist – information overload has to be avoided.
Contextualising this information in coherency with the software
This is one of the advantages of delivering this kind of information. If the software uses variables for contexts, these can be carried into the document. In this case, these are considered as carriable contexts. This is useful for eliminating unwanted content and pointing to pertinent procedures or questions for instance.
Contextualising to adapt to use cases or persona
User experience is a priority in modern software. Personas are adopted as a mechanism for identifying standard experience paths. Adapting to personas in content is the same as using carriable variables into the information, except that, in this instance, the content is adapted to the user. Onboarding a new user is catered for by this form of contextual information for software.
In our vision, contextual information for software is online, context sensitive, embedded adapted to software and persona contexts, and possibly triggered by software states or events.
To cut a potentially long story short, it’s connected to the UI at whatever level of molecularity you require.
Online information is not where we would recommend going to. Our proposed direction for information other than contextual is a portal. Arguably, this is online, but with a difference which is a lot more than a nuance: portals are the key step for using analytics, measuring pertinence and usability and gathering comments, feedback and know-how.
We’ll talk about software contexts, carriable contexts, triggered information a bit later in the article.
Contextual information structure is based on an editorial matrix
Standardising the information produced and catering for delivery cases means we have to have a matrix such as the one indicated above, to help writers and contributors to understand the type of information expected. This matrix is a guide.
By no means should it be seen as an exhaustive content requirement.
We need to consider several elements to help us understand how to build better contextual information for software:
- take the user profile into account by looking at user persona we have to deal with
- use the user profile to deliver adequate information to the right profile.
- determine if the software has carriable usage-related or data-related-contexts.
- isolate onboarding related content from the rest. Onboarding content is for one-time reading and should disappear from in front of the user at some stage.
Taking these elements into account renders the matrix multi-dimensional.
Personas as the basic profile segmentation for content
In the type of software we have to deal with, user personas can be considered being beginner, literate, proficient or expert.
To cater for these, we have to take the following content typology into account:
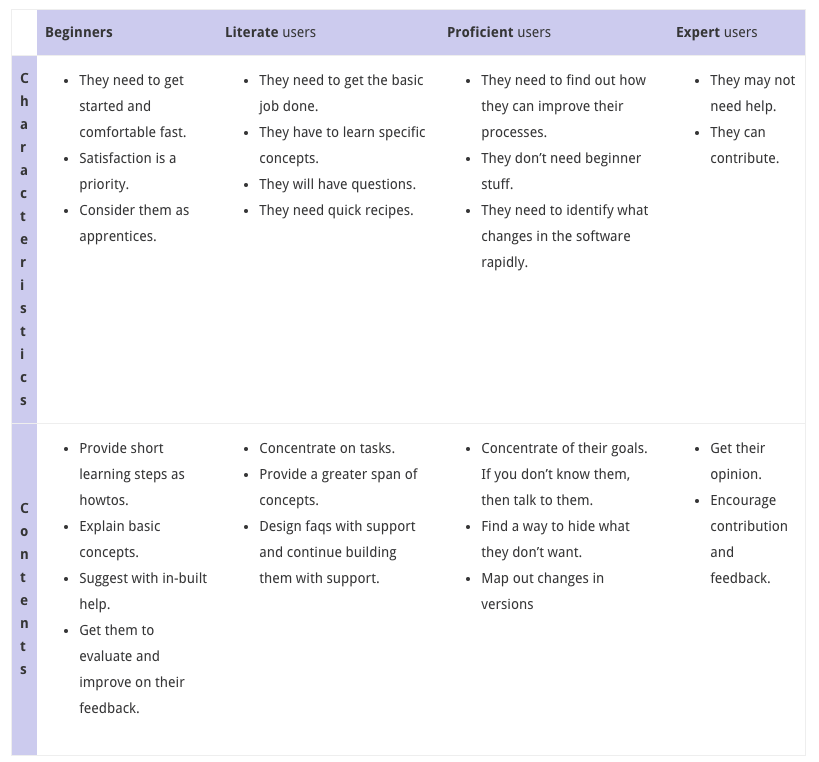
By Literate users, we mean those who are able to use the basic options and a bit more.
See: Computer literacy on Wikipedia – it’s far from the best, but at least it’s a starting point.
Taking this persona-based matrix into account, you can see that some information is no longer relevant for some of the categories dealt with above.
What’s the relationship between context and persona?
Context is a place or a state of a place (contextualised) in the software. Information is provided for these contexts and states.
A persona handles information or has requirements of different types in a given software context or state.
Some complex information, for instance, is useless to beginners, whereas beginner information is painful for experts.
The context hasn’t changed it’s the requirement which changes as experience evolves.
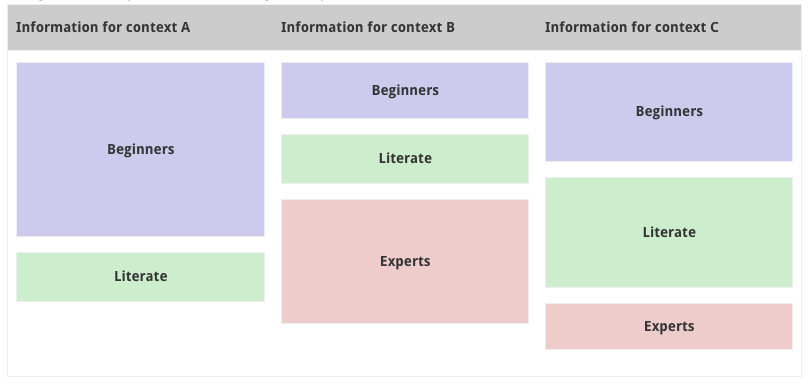
What’s the relationship between contextual information and a profile?
A profile is how a user considers himself and how he configures his software experience. OK, we probably haven’t learned anything new here.
What we are concentrating on is how we can allow a user to control what he sees in the UI and how he uses information that can be delivered.
In this situation several axes of profiling interest us:
- Users can identify with a persona – I’m a beginner, a proficient user or an expert, for instance.
- Users can decide to display onboarding information or not. They may be proficient in software, but not in new options, so turning this on and off has a meaning for them.
- Users can indicate domains of interest. This is based on a taxonomy tagging used in the software and in content tagging.
- Users can decide if they want to comment and/or contribute.
The crux is defining a mapping that is common to the software and the content. This is a technology layer.
What’s a carriable context?
What we mean by a carriable context is one defined in a specific technology domain that can be used in another technology domain. For instance, where contexts change – a process is finished and I can’t go back unless I do something or make a decision – the user requires different information than when he is in the middle of the process.
If his process failed, or he determines it went wrong, here again, the information requirement changes.
These are contexts that have to be carried to the information delivery mechanism.
What is triggered information?
This is not necessarily a new concept. See Triggering information by context by P. J. Brown.
Triggers are events or contexts in software, events in scenarios, events in support that trigger information produced for the context.
These triggers need to be carried across to an information delivery structure, which in turn has a mapping mechanism tuned for writing in the proper context.
The type of trigger reaction we would look for is one that requests information and gets both the content candidates and the format or container for display.
Content is not delivery
And you’re saying: « Of course, it’s not !».
Content can’t be delivered without being wrapped. We currently spend far too much time on the wrapping which changes as we change technology.
Information is just information. It has to be tagged and assembled – that’s DITA. Where it is used is multi-channel, multimedia, multi-context.
Currently, we export it, wrap it up and in the process make it static. That needs to end. What we are looking at is live data availability – this is more portal oriented. Software in the future will request content which will be delivered in a container adapter to its technology and UI, the context and the user preferences.
So information is media independent, and its qualification is real-time, with analytics and a means of reacting to it.
Information has to fit a context and so does the delivery.
Can the user decide how he wants to read and how?
Reading patterns evolve all the time and today we need to spend less and less time sifting through the spam or the decoration to get to the real information we want when we want it. Users will decide what they want.
They will also want to be able to decide where they want it.
Several examples come to mind:
- wanting procedural documentation display on my tablet instead of cluttering my UI.
- wanting reference information wrapped and sent to my email on with one click.
- wanting to store article for later reading.
- wanting to be reminded of a subject to look at while having a coffee.
- wanting a second opinion – for example, for a list of available experts on the subject.
- wanting to see a subject in the morning before starting anything else.
These are just a few ideas for a personal reading track.
How do we build contextual information for software?
In our tools we have a bottom-up approach, so we won’t develop the whole subject again here. If you want to know more, have a look at Document your product intuitively from the ground up.
Bottom-up construction starts with a micro-topic matrix for contextual information for software.
This is separated from subjects that do not have a direct, instantaneous benefit in-line.
They aren’t forgotten, they are added as links along a reading path. Part of our time is then spent writing and the rest is mapping out the part or journey to fit the personas we identified and our content clients.
Contextual information for software is minimalist by essence and is attached in context. This context is determined in conjunction with developers and product owners. This is a key collaboration point.
It will also help work on UI terminology and ergonomics in passing (but that’s another article).
Building is collaborative and agile
One person or team alone doesn’t have all the sources or know-how to deliver everything within real-world time constraints.
Collaboration is essential for content building, so the collaborators in the future won’t only be the information writers or designers, but all the stakeholders. Agile processes contribute to a rapid production cycle.
The future ambition is more about getting it out fast, make it just good enough and use analytics and reading measurements to decide what to do next. If it’s good enough, then it’s good enough. If it’s bad dump it. If a user contributes better, then incorporate that.
Actually integrating user content improves satisfaction all over and promotes an impression of proper catering.
Delivering contextual information for software today
Today we can export, publish. In our projects, what we do today, is deliver contextual information for software to a software repository, which in turn recognises it and displays it where necessary. Then information access is stepping through the links provided for further reading if contextual information is not enough.
Parallel publishing to product websites is also a vector we use. But all of this is static for the moment. In a lot of the projects we do, we stopped PDF delivery ages ago. A lot of people still publish to PDF.
When you publish or when you export to static formats, then you make versioning a real problem and add time-consuming issues to the workload.
Contextual information for software in the future
Well, the real question is, will it be delivered?
More than probably not, unless it has to go offline. So publishing in the future is exporting to a static instance and form because we have no other option.
All other information access will be to live data in real-time.
This also makes maintenance real-time and reactions real-time. Software products won’t get information delivered, they’ll ask for it.
To be more precise, individual users of a software product will tune a profile allowing them to define a reader profile and get real-time data on request or in information flows.
Information flows are typically for suggestions, tips & tricks.
With edc, we’ve taken all of these concepts into account and created a solution that takes us toward the next step of providing contextual information for software.

