

Il existe de nombreuses variantes dans les méthodes et la terminologie en fonction de la technologie utilisée, et elles ont beaucoup évolué : aide en ligne, aide contextuelle, aide contextualisée, aide ciblée, aide à l’intégration et bien d’autres.
Certaines définitions sont claires, d’autres sont liées à des technologies spécifiques. Ce que nous constatons, c’est qu’il y a beaucoup de chevauchements dans les définitions, car elles ont évolué au fil des ans.
Pour nous, le but de l’information contextuelle pour les logiciels est d’être fournie au bon moment, au bon endroit et avec un contenu adapté au contexte dans lequel elle est lue.
Le but de cet article est d’établir des définitions et des méthodes de production et de livraison à utiliser au fur et à mesure que nous évoluons vers les besoins de l’industrie 4.0
Google fait référence à l’aide en ligne :
L’aide en ligne est une information thématique, procédurale ou de référence fournie par le biais d’un logiciel informatique. Il s’agit d’une forme d’assistance aux utilisateurs. Elle est la plupart du temps conçue pour fournir une assistance dans l’utilisation d’une application logicielle ou d’un système d’exploitation, mais peut également être utilisée pour présenter des informations sur un large éventail de sujets. Lorsque l’aide en ligne est liée à l’état de l’application (ce que fait l’utilisateur), elle est appelée aide contextuelle.
From Google – Online help
Il existe de nombreuses solutions propriétaires pour créer de l’aide en ligne – l’article référencé ci-dessus en regorge.
Et Google fait également référence à l’aide contextuelle :
L’aide contextuelle est une sorte d’aide en ligne obtenue à partir d’un état spécifique du logiciel, fournissant une aide pour la situation associée à cet état.
L’aide contextuelle, contrairement à l’aide en ligne générale ou aux manuels en ligne, n’a pas besoin d’être accessible dans son entier pour être utilisée. Chaque sujet est censé décrire en détail un état, une situation ou une caractéristique du logiciel.
Une aide contextuelle peut être implémentée à l’aide d’info-bulles qui fournissent soit une description concise d’un élément d’interface, soit une rubrique complète à partir du fichier d’aide. D’autres moyens couramment utilisés pour accéder à l’aide contextuelle commencent par cliquer sur un bouton. Une méthode utilise un bouton par widget qui affiche immédiatement l’aide. Une autre méthode modifie change le pointeur en un point d’interrogation, puis l’aide s’affiche quand l’utilisateur clique sur un widget.
L’aide contextuelle est souvent (mais pas exclusivement) utilisée dans les interfaces graphiques. Les exemples incluent l’aide Balloon d’Apple System 7, WinHelp de Microsoft, OS / 2 INF Help, SupportPoint de Panviva ou l’aide JavaHelp de Sun.
Un sujet similaire est l’aide intégrée, qui peut être considérée comme une aide contextuelle «plus profonde». Elle va généralement au-delà des explications de base ou des clics manuels en détectant le besoin d’aide d’un utilisateur ou en offrant une explication guidée in situ. L’aide intégrée ne doit pas être confondue avec un assistant logiciel.
From Google – Context-sensitive help
Toujours là ?
Alors, quelle méthode utiliser, de l’aide en ligne, contextuelle ou intégrée ? Faut-il également ajouter des info-bulles ?
Nous pourrions probablement organiser une conférence et en débattre, mais nous ne le ferons pas.
Nous avons notre propre définition des informations contextuelles pour les logiciels.
Notre définition est de l’information contextuelle pour les logiciels
Les informations contextuelles pour logiciel sont fournies directement à un élément d’interface utilisateur au moment et à l’endroit où elles sont nécessaires.
Selon la technologie logicielle, cette forme d’information est intégrée ou connectée (auquel cas elle apparaît dans un élément contextuel).
Dans ce cas, elle est très différente de la définition de l’aide en ligne qui couvre généralement uniquement les pages accessibles au format web.
Les informations contextuelles sont un point d’accès à d’autres formes d’informations procédurales, de référence, conceptuelles, de formation et d’assistance par le biais de liens pertinents.
Les méthodes de rédaction utilisées ici sont basées sur DITA, où des micro-sujets sont écrits en cas de besoin. En tant qu’auteur, cela implique de poser les bonnes questions :
- Qu’est-ce que c’est et / ou qu’est-ce que ça fait ?
- Comment dois-je l’utiliser ?
- Faut-il un exemple ?
- Où suis-je en termes de workflow ?
- Et ensuite ?
- Quels pièges éviter ?
Ces questions sont une matrice éditoriale, une sorte de directive sur le contenu. En aucun cas tous les éléments ne doivent être rédigés de manière exhaustive comme s’il s’agissait d’un formulaire à remplir.
Le formulaire est minimaliste, il faut éviter la surcharge d’information.
Contextualiser l’information en cohérence avec le logiciel
C’est l’un des avantages de fournir ce type d’informations : si le logiciel utilise des variables pour les contextes, celles-ci peuvent être intégrées au document.
Dans ce cas, ceux-ci sont considérés comme des contextes transportables. Ils peuvent servir à éliminer le contenu indésirable et pointer vers des procédures ou des questions pertinentes.
Contextualiser pour s’adapter aux cas d’utilisation ou au personas
L’expérience utilisateur est une priorité dans les logiciels modernes. Les personas sont utilisées comme mécanisme d’identification des parcours d’expérience standard.
Adapter le contenu aux personas revient à utiliser des variables transportables dans l’information (sauf que, dans ce cas, le contenu est adapté à l’utilisateur). L’intégration d’un nouvel utilisateur est prise en charge par cette forme d’informations contextuelles pour les logiciels.
Dans notre vision, les informations contextuelles pour les logiciels sont en ligne, sensibles au contexte, intégrées, adaptées aux contextes logiciels et personnels, et éventuellement déclenchées par des états ou des événements logiciels.
Pour résumer, l’information est connectée à l’interface utilisateur au niveau de granularité dont vous avez besoin.
Nous ne recommandons pas d’utiliser de l’aide en ligne. La direction que nous proposons pour les informations autres que contextuelles est un portail.
Ce dernier est en ligne, mais avec une différence notable : les portails sont l’étape clé pour utiliser les outils analytiques, mesurer la pertinence et l’utilisabilité et recueillir des commentaires, des commentaires et du savoir-faire.
La structure d’information contextuelle est basée sur une matrice éditoriale
Normaliser les informations produites et prendre en charge tous les cas de livraison signifie que nous devons avoir une matrice telle que celle indiquée ci-dessus, pour aider les rédacteurs et les contributeurs à comprendre le type d’informations attendues. Cette matrice est un guide. Elle ne doit en aucun cas être considérée comme une exigence de contenu exhaustive.
Nous devons considérer plusieurs éléments pour nous aider à comprendre comment créer de meilleures informations contextuelles pour les logiciels :
- prendre en compte le profil de l’utilisateur en examinant la persona de l’utilisateur auquel nous devons faire face (voir notre article à ce sujet)
- utiliser le profil utilisateur pour fournir des informations adéquates au bon profil
- déterminer si le logiciel a des contextes liés à l’utilisation ou aux données
- isoler le contenu intégré est destiné à une lecture unique et devant disparaître quand l’utilisateur n’en a plus besoin.
La prise en compte de ces éléments rend la matrice multidimensionnelle.
Les personas comme segmentation de profil de base pour le contenu
Dans le type de logiciel auquel nous devons faire face, les personas utilisateurs peuvent être considérées comme débutants, intermédiaires, compétents ou experts.
Pour y répondre, nous devons prendre en compte la typologie de contenu suivante :
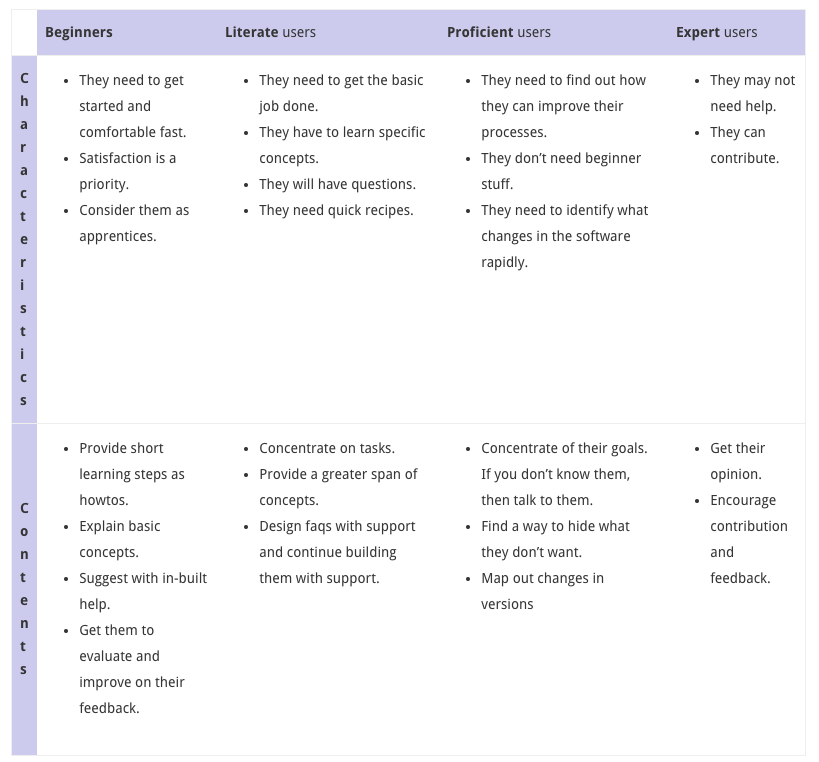
Par utilisateurs intermédiaires, nous entendons ceux qui sont capables d’utiliser les options de base et un peu plus.
En tenant compte de cette matrice personnalisée, vous pouvez voir que certaines informations ne sont plus pertinentes pour certaines des catégories traitées ci-dessus.
Quelle est la relation entre le contexte et la persona ?
Le contexte est un lieu ou un état d’un lieu (contextualisé) dans le logiciel.
Des informations sont fournies pour ces contextes et états.
Une persona gère des informations ou a des exigences de différents types dans un contexte ou un état logiciel donné.
Certaines informations complexes, par exemple, sont inutiles pour les débutants, tandis que les informations pour débutants sont douloureuses pour les experts. Le contexte n’a pas changé, c’est l’exigence qui change à mesure que l’expérience évolue.

Quelle est la relation entre les informations contextuelles et un profil ?
Un profil est la façon dont un utilisateur se considère et comment il configure son expérience logicielle. Ce sur quoi nous nous concentrons, c’est comment permettre à un utilisateur de contrôler ce qu’il voit dans l’interface utilisateur et comment il utilise les informations qui peuvent être fournies.
Dans cette situation, plusieurs axes nous intéressent :
- les utilisateurs peuvent s’identifier à une persona (je suis un débutant, un utilisateur compétent ou un expert, par exemple)
- les utilisateurs peuvent décider d’afficher ou non les informations d’intégration. Ils peuvent être compétents en logiciels, mais pas en nouvelles options, donc l’activer et le désactiver a un sens pour eux
- les utilisateurs peuvent indiquer des domaines d’intérêt. Ceci est basé sur un marquage de taxonomie utilisé dans le logiciel et dans le marquage de contenu
- les utilisateurs peuvent décider s’ils souhaitent commenter et / ou contribuer
Le cœur de la question est la définition d’une cartographie commune au logiciel et au contenu.
Il s’agit d’une couche technologique.
Qu’est-ce qu’un contexte transportable ?
Un contexte transportable est défini dans un domaine technologique spécifique et peut être utilisé dans un autre.
Par exemple, lorsque les contextes changent – un processus est terminé et je ne peux pas revenir en arrière à moins d’agir ou prendre une décision – l’utilisateur a besoin d’informations différentes par rapport à une autre étape du processus.
Si son processus a échoué, ou s’il détermine qu’il s’est mal passé, là encore, l’exigence d’information change. Ce sont des contextes qui doivent être transmis au mécanisme de fourniture d’informations.
Qu’est-ce qu’une information déclenchée ?
Ce n’est pas nécessairement un nouveau concept.
Lire Triggering information by context by P. J. Brown.
Les déclencheurs sont des événements ou des contextes dans le logiciel, des événements dans des scénarios, des événements dans la boucle de support qui déclenchent l’affichage d’informations produites pour le contexte.
Ces déclencheurs doivent être transmis à une structure de livraison d’informations, qui à son tour dispose d’un mécanisme de mappage réglé pour un contexte approprié. Le type de réaction de déclenchement que nous recherchons est celui qui demande des informations et obtient à la fois les contenus candidats et le format ou le conteneur à afficher.
Le contenu n’est pas la livraison
Et vous vous dites: « Bien sûr que non !« .
Le contenu ne peut pas être livré sans être encapsulé. Nous passons actuellement beaucoup trop de temps sur un emballage qui change dès que nous changeons de technologie.
L’information n’est que de l’information.
Elle doit être étiquetée et assemblée – c’est à ça que sert DITA quand il est utilisé en multicanal, multimédia, ou multi-contexte. Actuellement, nous exportons, enveloppons et le rendons statique l’information. Cela doit cesser.
Ce que nous voulons, c’est la disponibilité des données en direct – comme dans un portail. À l’avenir, le logiciel demandera du contenu qui sera livré dans un adaptateur de conteneur à sa technologie et à son interface utilisateur, au contexte et aux préférences de l’utilisateur.
L’information est donc indépendante des médias et sa qualification est en temps réel.
L’information doit s’adapter à un contexte, tout comme la livraison.
L’utilisateur peut-il décider de ce qu’il veut lire et comment ?
Les schémas de lecture évoluent en permanence, et nous avons de moins en moins de patience pour filtrer l’inutile pour obtenir les vraies informations que nous voulons quand nous le voulons.
Les utilisateurs décident de ce qu’ils veulent et d’où ils le veulent.
Voici quelques exemples :
- afficher la documentation procédurale sur ma tablette au lieu d’encombrer mon interface utilisateur
- recevoir les informations de référence zippées par e-mail en un seul clic
- stocker l’article pour une lecture ultérieure
- se souvenir d’un sujet à regarder tout en buvant un café
- avoir un deuxième avis – par exemple, pour une liste d’experts disponibles sur le sujet
- voir un sujet le matin avant de commencer autre chose.
Ce ne sont que quelques idées pour une piste de lecture personnelle.
Comment créer de l’information contextuelle pour les logiciels ?
Dans nos outils, nous avons une approche ascendante qui commence par une matrice de micro-sujets pour les informations contextuelles des logiciels.
Celle-ci écarte les sujets qui ne bénéficient pas d’un accès direct et instantané en ligne. Ils ne sont pas oubliés, ils sont ajoutés sous forme de liens le long d’un chemin de lecture.
Une partie de notre temps est ensuite consacrée à l’écriture et le reste à la cartographie du chemin d’utilisation des personas que nous avons identifiées et de nos clients.
Les informations contextuelles pour les logiciels sont minimalistes par essence et sont attachées au contexte. Ce contexte est déterminé en collaboration avec les développeurs et les product owners. Il s’agit d’un point de collaboration clé. Il faut également travailler sur la terminologie et l’ergonomie de l’interface utilisateur au passage (mais c’est un tout autre sujet).
La construction de l’aide est un processus collaboratif et agile
Une personne seule ou une équipe isolée ne dispose pas de toutes les ressources ou du savoir-faire nécessaire pour tout fournir en temps et en heure.
La collaboration est essentielle pour la création de contenu : à l’avenir, les collaborateurs ne seront pas seulement les rédacteurs d’informations ou les concepteurs, mais toutes les parties prenantes. Les processus agiles contribuent à un cycle de production rapide.
L’ambition future est de sortir plus d’information, plus rapidement, de la rendre juste assez bonne pour être utilisée et d’utiliser des analyses et des mesures de lecture pour décider quoi faire ensuite.
Si un utilisateur contribue, incorporez-le au cycle de création.
L’intégration effective du contenu utilisateur améliore la satisfaction de tous.
Fournir des informations contextuelles aux logiciels d’aujourd’hui
Aujourd’hui, nous pouvons exporter, publier. Actuellement, nous fournissons des informations contextuelles à un référentiel dans le logiciel, qui à son tour les reconnaît et les affiche si nécessaire. Ensuite, l’accès à l’information passe par les liens fournis pour une lecture plus approfondie si les informations contextuelles ne suffisent pas.
La publication parallèle sur les sites Web de produits est également un vecteur que nous utilisons. Mais tout cela est statique pour le moment. Dans de nombreux projets que nous menons, nous avons interrompu la livraison des PDF depuis longtemps. Beaucoup de gens publient toujours au format PDF. Lorsque vous publiez ou exportez vers des formats statiques, vous créez un véritable problème de versionnage complexes et chronophages à gérer.
L’information contextuelle pour les logiciels du futur
Eh bien, la vraie question est, sera-t-elle livrée ?
Probablement pas, à moins qu’elle ne soit mise hors ligne. Donc, en l’absence d’autre option, publier signifiera exporter vers une instance et un formulaire statiques.
Tous les autres accès à l’information seront des données en temps réel. La maintenance et les réactions seront donc également en temps réel. Les logiciels ne recevront pas d’informations, ils les demanderont. Pour être plus précis, les utilisateurs individuels d’un produit logiciel régleront un profil leur permettant de définir un profil de lecteur et d’obtenir des données en temps réel sur demande ou dans les flux d’informations. Les flux d’informations sont généralement destinés aux suggestions, trucs et astuces.
Avec edc, nous avons pris en compte tous ces concepts et créé une solution qui nous emmène vers la prochaine étape de la fourniture d’informations contextuelles pour les logiciels.

